An Introduction to Building and Exploring Datasets¶
Paul Opperman
January 1, 2018
paul@newportdataproject.org
Introduction¶
The Newport Data Project looks at our community through data. Although many people think of data as a bunch of numbers, data are really any pieces of information that describe something. According to Wikipedia,
Data as a general concept refers to the fact that some existing information or knowledge is represented or coded in some form suitable for better usage or processing.
Newport Data Project's work focuses on collecting sets of information to tell a story, answer a question, or solve a problem. To be able to tell a story using data, we need to be able to work with it. In this document we'll walk through the process of building the sidewalk dataset and introduce some tools to explore data. The general process we'll follow is:
- Ask a question
- Find information
- From real world observations
- From secondary sources, like the web (and this list of data portals)
- Organize the information in a useful format, and share it
- Spreadsheet or delimited file (i.e. .csv)
- Geospatial file (e.g. ESRI shapefiles, GeoJSON)
- others...
- Explore the data to answer the question
- Ask new questions! (and go back to 1)
A note about technology¶
A few different tools are used in this example, ranging from a pen and paper to spreadsheets, to gps tracking, in-depth geographic information software and custom computer code. A few things to keep in mind:
- Finding data is often the lowest-tech step, but the most challenging and most important part of the process
- Not everything can or should be done with code
- The answers are in the data, not the tools
Let's get started!¶
Question: Where are the sidewalks?¶
If you've walked around Newport, you may have noticed the, um, quirky qualities of our sidewalks. You probably know that they are only on one side of some streets, end halfway down a block on others, and just don't go places one might expect. But probably no one can draw a detailed accurate picture, or quantify how many streets don't have sidewalks. To begin to answer this question completely, we need to document the sidewalks and organize the information into one place. That is, we need to build a dataset.
Collecting Data¶
The central part of our question is: "where?" This suggests that we are looking for something we can put on a map. In other words, it's geospatial data. Fortunately, for this question we can just take a walk and collect data ourselves! We can collect gps data with a smartphone using apps like this to record a walk along a sidewalk.
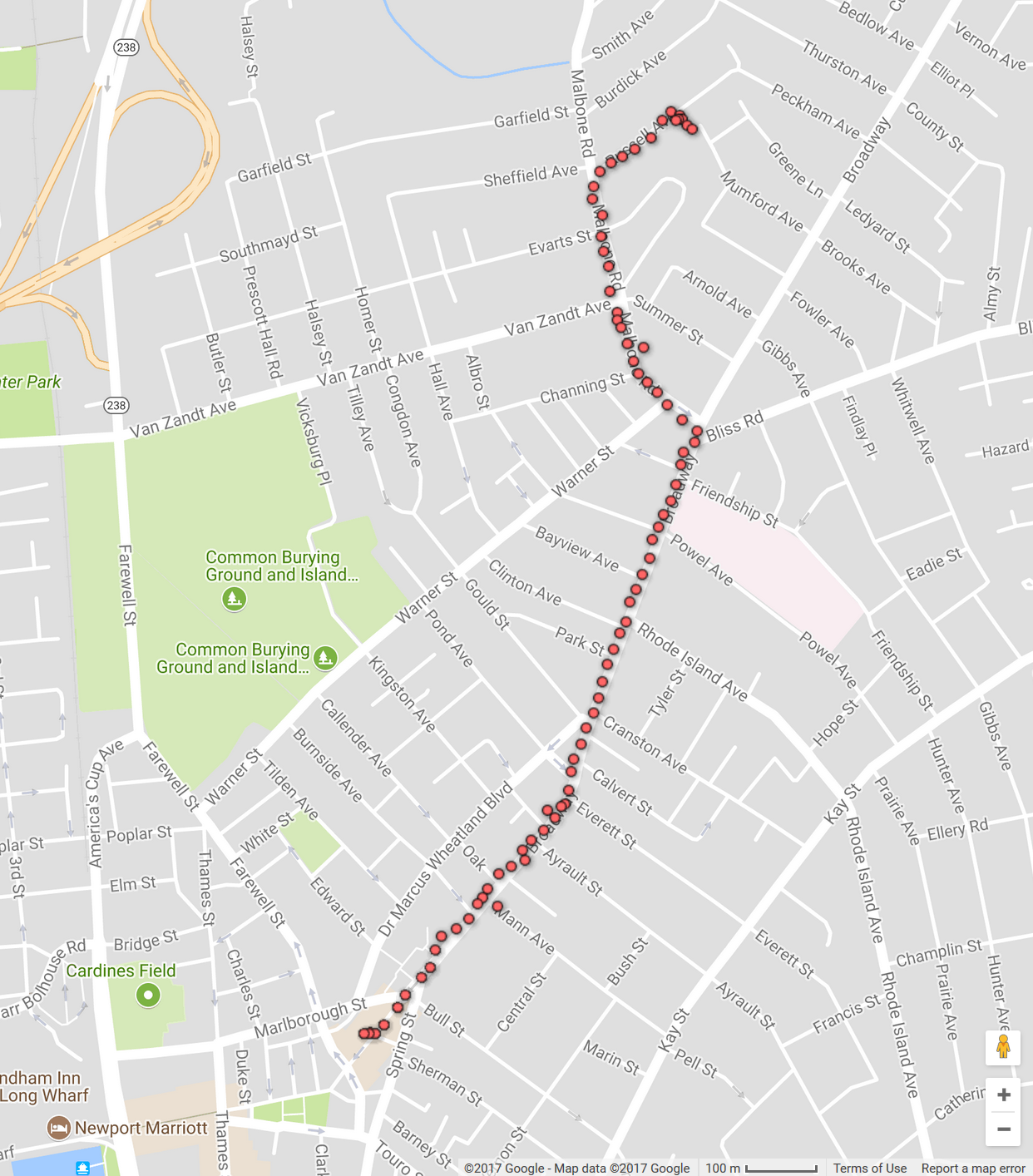
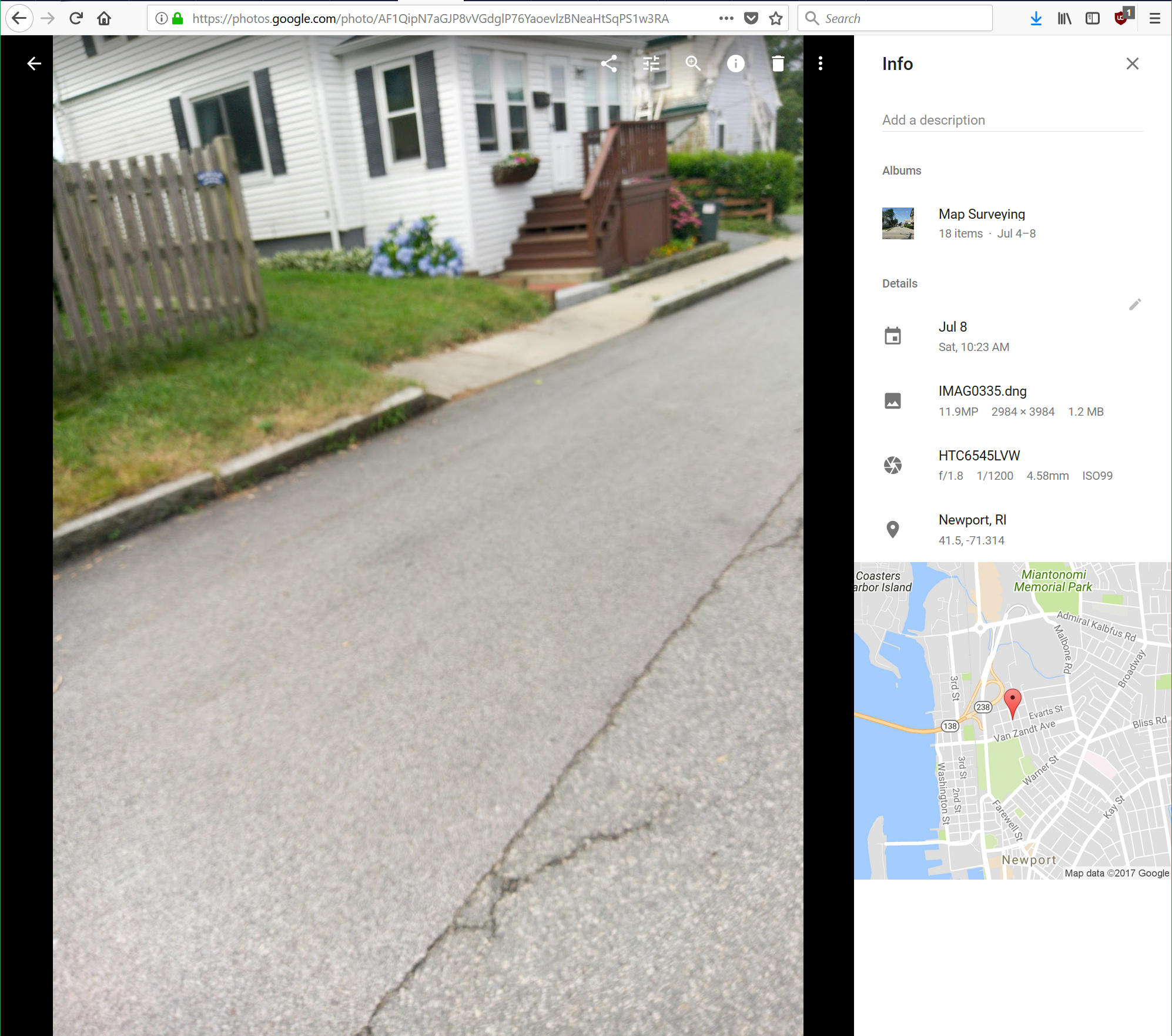
And we can take geotagged photos where we need more detailed records.
We can also use publicly available (and appropriately licensed) information to help build our dataset. Bing has aerial imagery that is open for use, so we can find sidewalks from a computer.
Compiling a Dataset¶
With all the information we've collected, we need to get it organized in a useful format. Since we collected sidewalk data in a few different formats, we compile all the information by hand using the Geographic Information System (GIS) software QGIS by drawing the lines representing sidewalks. This software puts all the information we collected into a standard geospatial data format that can be used by many different applications (you can check it out here). Assuming we've done a good job cataloging sidewalks in Newport, we have a dataset that answers our question. At this point we save the map and post it to the data portal for people to use.
Working with the Dataset¶
Now that we have a dataset of sidewalks in Newport, we can start working with it. There are lots of different ways to explore the data (like QGIS or Tableau). For this example we'll be using a python library called geopandas. The first thing we need to do is import the python tools we're going to use.
import requests
import geopandas as gpd
import fiona
import matplotlib.pyplot as plt
Read the data¶
We start by using the requests package to read the data from the Newport Data Portal. This code pulls the data and then shows us what we got.
# read the sidewalk map file from the data portal
sidewalk_response = requests.get('https://raw.githubusercontent.com/NewportDataPortal/sidewalk-map/development/npt-sidewalks.geojson')
# look at a piece of the raw dataset
print(str(sidewalk_response.json())[:2000] + " ...")
JSON strings are nice for storing and transmitting data, but there are much better formats to work in once we have it loaded. The code below coverts the data we downloaded into a handy geopandas package. Compare the geopandas data output below with the raw JSON above.
# Nothing to see here, just some hacky python code to get the dataset formatted so it can be read in by geopandas.
# reference https://gis.stackexchange.com/questions/225586/reading-raw-data-into-geopandas
b = bytes(sidewalk_response.content)
with fiona.BytesCollection(b) as f:
crs = f.crs
sidewalk_gdf = gpd.GeoDataFrame.from_features(f, crs=crs)
# take a peek at the data
sidewalk_gdf[30:40]
Clean the data¶
That's much easier to read, right? You can start to understand the data, and find errors or inconsistencies. (Hint: take a look at row 32.) Let's fix that.
sidewalk_gdf.iloc[32]['name'] = 'Warner St'
sidewalk_gdf.iloc[32]['surface'] = 'None'
sidewalk_gdf[30:40]
Visualize the data¶
Often, large datasets are easier to understand when they are visualized in some way. Data processing libraries like geopandas make it easy to work with your data and generate plots. For example, we can plot a basic map of the sidewalks with this simple code:
# plot a map
sidewalk_gdf.plot(figsize=(28,14), color='g')
plt.show()

Another question: How many people live near the sidewalks?¶
It's great that we know where the sidewalks are, and can draw them on a map. But how can we start applying it to our community? Sidewalks are for people, so let's see where the people are.
Finding more datasets¶
For this question, we need two pieces of information - how many people there are in a location. We are looking for another geospatial dataset, but this time we need the additional information of the number of people.
A good place to start looking for new data is the internet. You can see what we get from Google with the search "population in newport ri" here. The top results are for total population which may be useful in some cases, but we want to know where people live within the city. If you dig far enough into the US Census Bureau, you can find the 2010 Census summary file 1 data. In raw form, this is a very complex dataset (the technical documentation for this dataset is a 730 page pdf). Fortunately, RIGIS did some of the hard work for us and has a usable dataset posted online, with an api for us to access. We can load it in the same way we did with the sidewalk map.
# download census data from rigis api
rigis_api_path = "https://opendata.arcgis.com/datasets/7489a7517b8e46728db2a26d9a258c39_0.geojson"
census_response = requests.get(rigis_api_path)
b = bytes(census_response.content)
with fiona.BytesCollection(b) as f:
crs = f.crs
census_gdf = gpd.GeoDataFrame.from_features(f, crs=crs)
# print the first 10 entries
census_gdf.head(10)
Processing the dataset¶
There is a lot of data here! We only want total population data for Newport, so we can extract that from the whole dataset by filtering on the column RIMUNI10.
# filter and extract Newport city data entries
newport_census = census_gdf[census_gdf['RIMUNI10']=='Newport city']
# print the first 10 entries
newport_census.head(10)
To find out which column represents the total population in each census block, we should check out the metadata, which you can find here. (Hint: it's POP1). Now we know how to find the information to answer our second question.
There's a lot more information in the dataset. Explore the metadata to see what else you could find out.
Plot the data¶
We can now build a map showing how populations are connected to sidewalks. The population data is represented as a choropleth map, where darker colors indicate higher populations in the area (note, we aren't normalizing the population based on land area, so it's not the best visual representation of the data). We'll add the streets to the map as well to get an indication of where sidewalks aren't.
(We're glossing over the steps taken to find the streets dataset, but it is the same basic process we used to find the census data. Now that we have it, we'll keep it for future use).
# get roads data from RIGIS
rigis_roads_api = "https://opendata.arcgis.com/datasets/30943d3301474c1abbf79912cd11b25c_0.geojson"
roads_response = requests.get(rigis_roads_api)
b = bytes(roads_response.content)
with fiona.BytesCollection(b) as f:
crs = f.crs
roads_gdf = gpd.GeoDataFrame.from_features(f, crs=crs)
# filter roads for just newport
newport_roads = roads_gdf[roads_gdf['LTWN']=='NEWPORT']
# plot the census choropleth map as the base, and overlay the sidewalk map.
base_plot = newport_census.plot(column='POP1', cmap='PuRd', figsize=(16,16)) # base layer
rds_plot = newport_roads.plot(ax=base_plot, color='k') # add roads layer
sidewalk_gdf.plot(ax=rds_plot, color='g') # add sidewalk layer
plt.show()

We could probably start telling a story with this map!
Data limitations¶
One thing to keep in mind is that datasets are rarely perfect. They may be outdated, or may have errors or missing data. For example, the bridge to Goat Island has a sidewalk, but the sidewalk map data doesn't capture it (for now), and the census is from 2010. This doesn't make the entire dataset invalid, but it impacts the conclusions we can draw from it. If a dataset surprises you, try to figure out why.
Conclusions¶
This document follows the question "Where are the sidewalks?", taken from real-world, day-to-day experience through the steps to find, collect, and analyze the data to answer it. This is the approach we try to use in the Newport Data Project. Hopefully you were able to follow along to see how the walks around the city turned into the map above. This example only scratched the surface - there are more questions to ask like "Can people walk safely where they need to go?", and "Are these sidewalks accessible to everyone?" We just need to follow the same process with these new questions.
Data collection and exploration are the critical first steps to develop data based solutions for our community. Here are the things you should remember:
Keep asking questions¶
This is an iterative process. No single dataset has all the answers, and when you start exploring data you'll find gaps. The information is out there! You might be able to find another dataset to merge, or you may have to go collect the data yourself. Start with a new question and work from there.
Collecting data is the hardest part, so sharing is good!¶
People, companies, and governments spend a vast amount of resources to collect data. In this example we used a combination of real world observations and the work of others to build our dataset. We publish our sidewalk data online (with the rest of our data) to help the next group tell their story.
Information comes in many forms - use them all!¶
Data is not just numbers. It can be a collection of pictures, a list of names and addresses, or the text of the legal code. Tools exist to work with all types of data - the important thing is to make the data structured and readable by the tools.
The answers are in the data, not the tools¶
Our goal is to learn about our community, and take what we learn to solve problems and meet challenges. Data is the link to the community. We are building a comprehensive toolbox, and we can use it to find new insights in old data, and collect new data that's never been looked at before. Different tools can give us different insights, and no one tool can find all the answers, but the right tool won't work with the wrong data. Don't let tools get in the way of the data.